Failover Clustering provides high availability to core Windows services. Microsoft failover clusters ensure that if one server stops functioning there are redundant server resources to ensure that your applications continue to function.
For example, if a cluster enabled database goes down, the database will be restarted on another cluster node so that continuous access is available.
Contact us today to learn more about how we help with Failover Clustering.
DESIGN REQUIREMENTS
We can help with the necessary design decisions needed to maximize application availability.
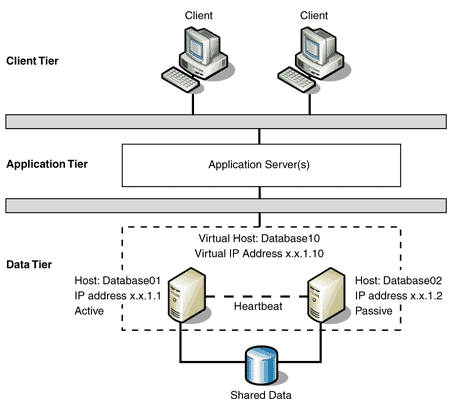
CLUSTER WITNESS
The most common size for a failover cluster is the minimum two-node cluster. In high-load environments, a cluster may have many server nodes.
NODE RELIABILITY
Failover clusters usually use all available techniques to make the individual systems and shared infrastructure as reliable as possible.
Failover clustering Reliability includes features like; disk mirroring, redundant network, redundant storage area network, and redundant electrical power. You need to be up and running at all times.
FAILOVER STRATEGIES
There isn’t a single high-availability cluster systems to handle failures in distributed computing. There are different strategies.
FAIL_FAST wherein the try fails if the first node cannot be reached, ON_FAIL_TRY_ONE_NEXT_AVAILABLE which tries one more host before giving up, and ON_FAIL_TRY_ALL_AVAILABLE: which tries all existing nodes before giving up.
Failover Clustering
About Failover Clustering
Most server features and roles can be kept running with little to no downtime.
We may request cookies to be set on your device. We use cookies to let us know when you visit our websites, how you interact with us, to enrich your user experience, and to customize your relationship with our website.
Click on the different category headings to find out more. You can also change some of your preferences. Note that blocking some types of cookies may impact your experience on our websites and the services we are able to offer.
Essential Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refuseing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Other external services
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.